Ethereum分片
 次阅读
次阅读
文章目录
背景
- 交易TPS的限制
- 存储数据的浪费
- 缺乏并行能力
核心目标
增强区块链的处理能力,首先降低数据的存储压力,其次增强区块链的处理能力
技术分类
- Layer 2,在线下处理,仅将结果上链
- 对共识等做修改,分片即为此类方式
分片的整体思路
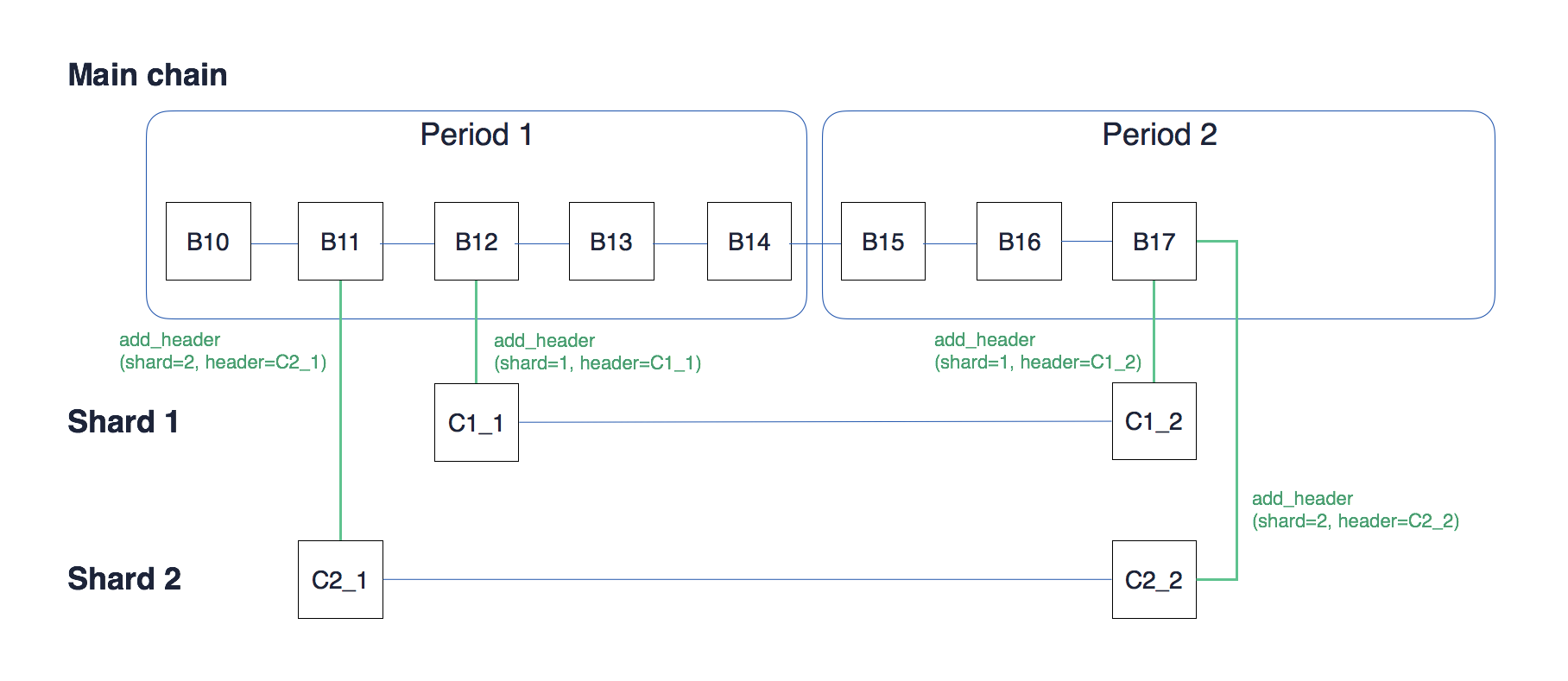
分片可以认为包含两个链,一个是主链(mainnet chain),一个是各个分块链(shard chain)
两者之间的关系可以这么认为,基本的交易是最底层的数据,分块链是存储的各种交易内容,然后主链存储的是分块链中的核心数据(后面提到的collation header)。
在上图中,还有个Period的概念,这个的目标是为了在一定时间后更新分片中的验证节点。目前定义一个period_length(周期长度)是5个区块,即每5个区块就会更新下分片的验证节点。
对比图如下:
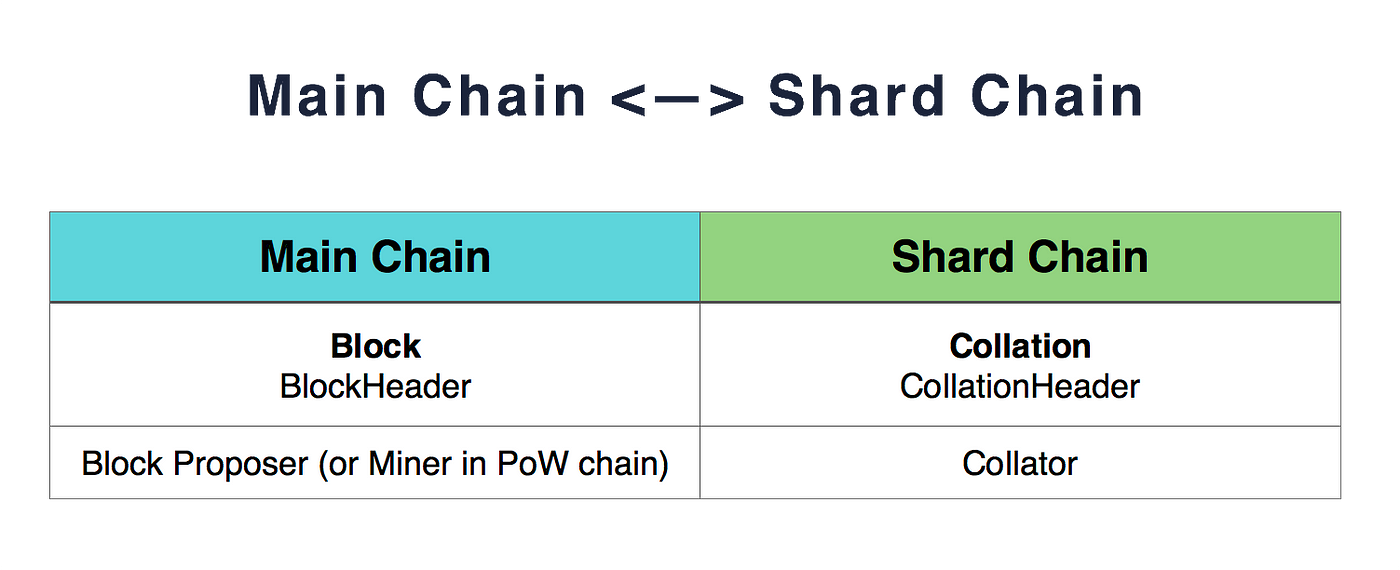
校对块
每个分块的数据叫做collation(有些人翻译成校对块),其中校对块是由一些collator(校对人)进行校验,判断正确后,将相关的collation header(校对块头)写入到主网链中。
校对块的结构如下所示

- shard_id就是分片的id序号,目前以太坊准备设计100个分片
- expected_period_number是collation(校验块)期待被包含的进的周期序号。如分片所说,一个period=floor(block.number/period_length)
- Period_start_prevhash指的是上一个周期的最后一个区块hash
- parent_collation_hash指的是上一个collation的hash(一个周期中的同一个分片可能会有多个collation,当然也有可能是前一个周器中的本分片的collation的hash。总之就是本分片的最后一个打包进去的collation的hash)
- tx_list_root就是指的本collation所有交易树的根。
- coinbase本collation生成者的地址。
- post_state_root指执行完本collation的所有交易之后,最新的状态树的根,和之前的区块链的状态根含义是一致的。
- Receipt_root指收据树的根hash
- sig签名
- Transaction List 就是打包进本分片的交易内容
此外,根据分片doc文档所描述,在collation header中有个number,指的是collation number,含义根据理解,应当等同于blockchain中的number或者height,也就是分片中校验块的高度。根据官网描述,本含义也是在进行分叉选择规则时所需要参考的数值(后叙会提到)。
打包入主网链
目前以太坊的分片使用一个VMC(validator manager contract),功能是用来进行分片管理的,暂时不进行详细描述。将校验块打包入主网时,会有一系列流程。
首先会调用VMC的一个addHeader方法。会做以下判断:
- shard_id符合要求,不能超过总的数目,目前定义是最多100个分片
- Ecpected_period_number符合要求,满足前面提到的计算公式
- parent_collation_hash和Period_start_prevhash都已经验证通过了,换句话描述就是这两个都已经被接受了。(目前PoW实际不是最终显示一致性的,但是以太坊的Casper声称已经结合PoS以及BFT做到了一致性,论文需要后续研读)
- 本collation不能重复(和以太坊1.0验证是一样的)
- 本collation的提交者,或者叫collator是属于本分片的。(如何为每个分片选择合理的集合很重要)
其次,会判断本校验块结果是否正确。由于在验证校验块头(collation header)时验证了parent_collation_hash已经存在并默认正确,本步会验证parent_collation_hash所对应的state_root和receipt_root执行本collation里面的交易得到的结果,是否会和本collation header中的state_root和receipt_root是否一致
最后会验证是否符gas要求。
以上验证通过,会将本collation header写入主网的区块中。
合法链选择原则
以太坊1.0存在分叉,2.0也不可避免的会存在分叉。因此,需要考虑在存在分片的情况下,如何选择最合理的链。
最基本的原则是依赖最长主链,但是有一定的改动。
如下图所示:

毫无疑问,选择的是B3这条链,选择的也是里面的分片数据。
假设现在有一个B3'连接到了B2'
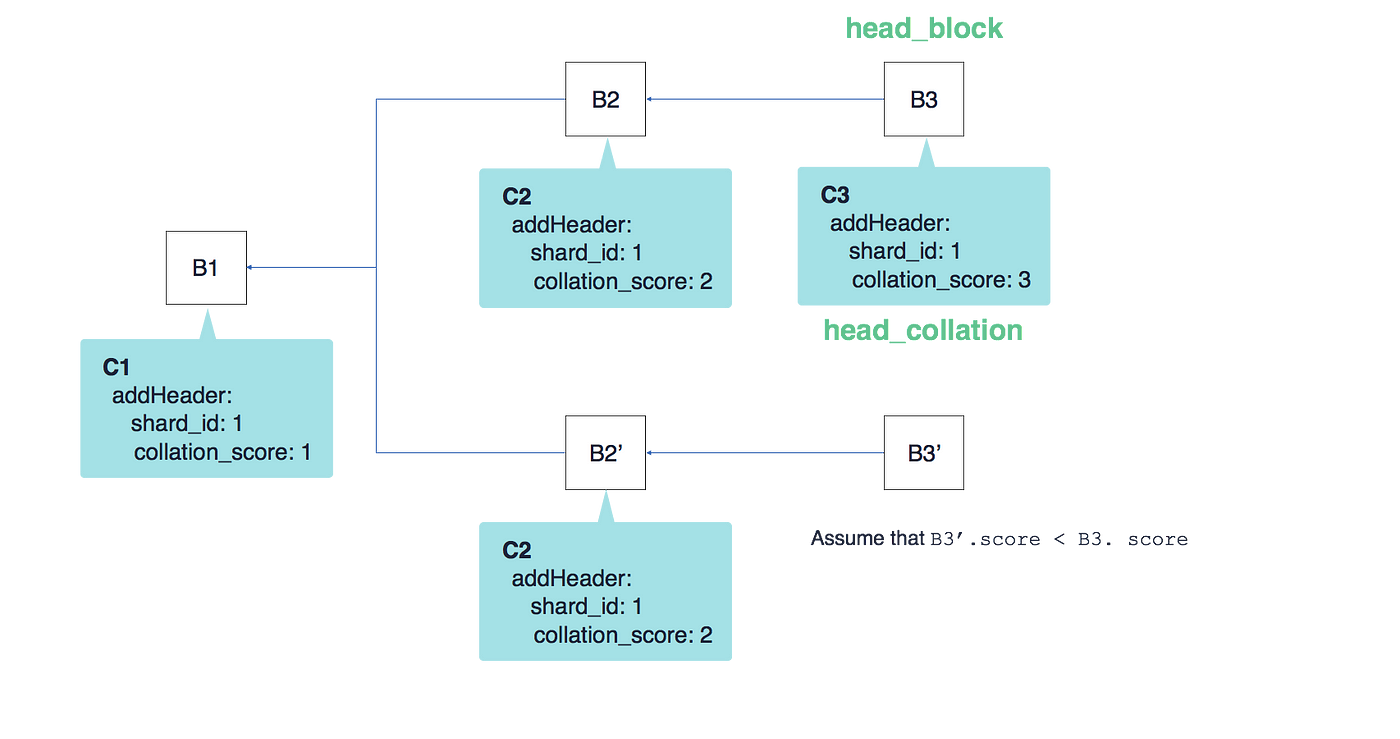
此时,假设B3'的分数没有B3所在的链大(分数指的是校验块的分数,即上面提到的number)
现在假设有了一个最新的区块B4'连接到了B3',如下所示
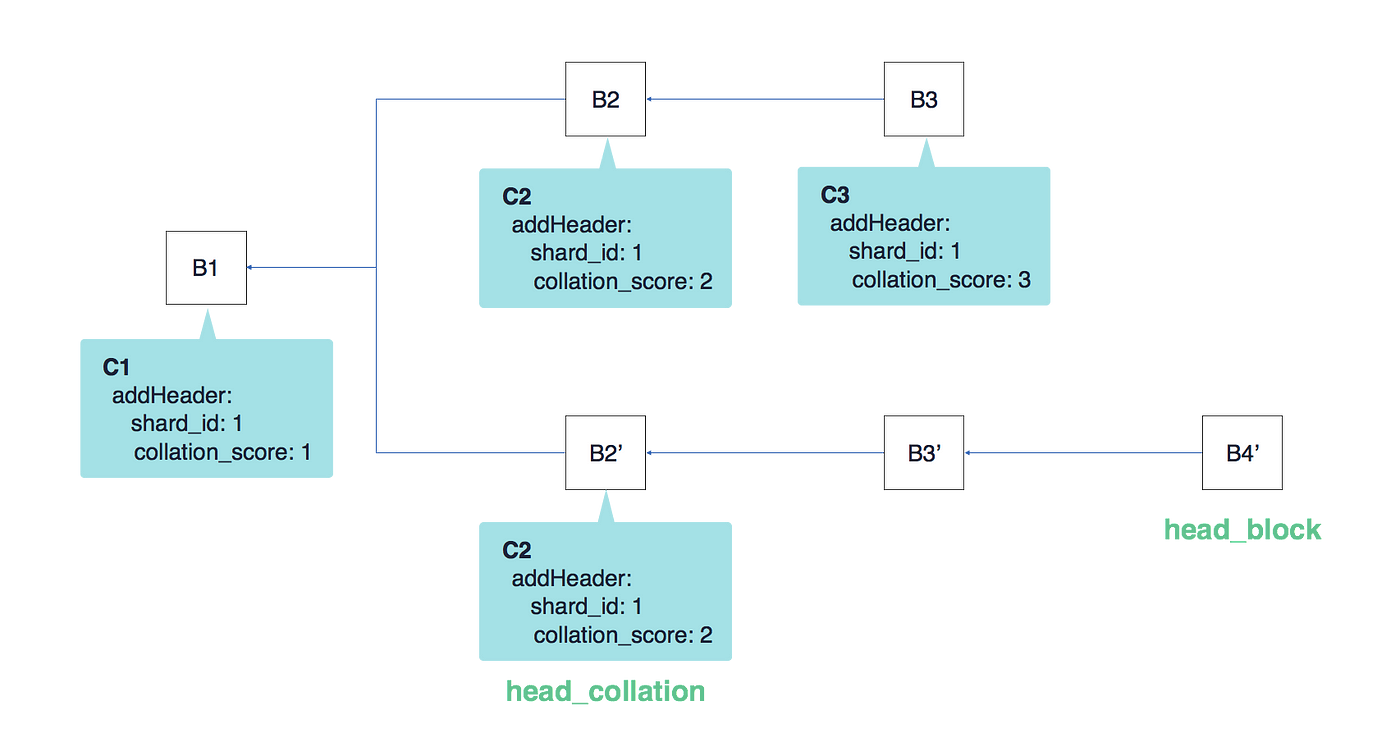
很明显,B4'所在的链虽然分片的总分数不是最大,但是主链长度最长,所以依然选择B2'的分片为合理的分片数据。
综上,选择合理的链的时候,优先看链的长度,在长度一致的时候,优先选择分数最大的链。
collator选择
在全网进行数据共识时,PoW的攻击者需要51%的算力才能攻击成功,现在进行分片后,如果没有设计合理的分片方法,有可能会将恶意节点分到同一个分片中或者恶意节点提前准备,进入同一个分片,系统的安全性会大大降低。也就是1%攻击

为了防止此类问题,一个不可提前预知的,人为难以干预的,可以被验证的分片校验验证节点选取算法非常有必要。
在sharding doc上,提出了一个简单的节点选取算法
|
|
可以看到,大体的算法是使用区块哈希+分片ID生成基本数据,然后从节点集合里面取模计算,获取合理的节点。可以看到,这个方式能够防止提前计算,还可以被合理验证。
同步
根据前面的了解,我们知道每个分片的验证节点每隔一个period是会变化的,所以在period_1的shard_1的节点集合V_1经过验证,进入period_2后,shard_1的节点集合是V_2,V_2并没有之前的数据(这个更新节点集合流程叫做reshuffling),需要考虑怎么验证数据正确性。在2.0的设计上,此类节点叫做无状态客户端。(需要进一步阅读,确定这一理解是否正确)

现在矿工发送了一个新的交易区块B,验证者存有在这个区块之前的state_root。为了让验证者不需要存储所有的以往交易数据,旷工在发送交易区块B时,附带一个证据W,这个证据的内容是区块B中修改的数据的merkle证明。这样验证者验证证据的合法性,然后通过证据验证区块的合法性,最终区块通过。
只是,这个流程存在一定的问题:
- 证据谁来生成?而且,在发布交易时的merkle树和在打包交易时可能不一致,已经发生了变化。为了解决这个问题,可以让矿工保存过去24小时的数据,然后可以修改证据W,这样就解决了交易的问题。
- 状态谁来存储?以为最后,为了完整的验证,还是需要节点去判断交易的正确性,需要同步数据来判断结果。官方research提出有几种解决办法:
- 由全节点提供,默认保存一定时间;
- 用户掏钱,让别的节点来存;
- 用户自己存;
- 设计专门的存档节点;
对于问题1,有些建议矿工不需要存储24小时,因为会影响默克尔根的时间,只有从发布交易到交易入块这段时间。作者考虑到在一些极端场景下,如果交易延迟比较大,会失去内容,所以不建议过短。
其他
根据目前在网上的了解,以太坊2.0的进展目前在phase 1,还在做基本的分片,对于更新的分片之间的通信,暂时还没有新的进展。
后续的内容包括双向锚定、collation header的处理方式、数据可用性证明等等。